Contrairement au dernier épisode sous openbsd 5.9 l’installation de ruby on rails sur Openbsd 6 est un peu plus compliquée (j’aime les euphémismes).
Contrairement au dernier épisode sous openbsd 5.9 l’installation de ruby on rails sur Openbsd 6 est un peu plus compliquée (j’aime les euphémismes).
Il vous faut :
OpenBSD tout neuf a priori, ou non.
Il faut d’abord installer votre éditeur de texte préféré (j’ai dit vim ? ).
Puis installation de ruby
# pkg_add ruby
On vous propose différentes versions j’ai choisi à ce jour le 2.3 – choix 4.
L’installation de ruby est un peu étrange au sens ou elle installe des exécutifs finis par le numéro de version. Ainsi ruby 2.3 devient ruby23 dans /usr/local/bin, idem pour les autres exécutables (bundle, bundler, rake etc…). Je pressens quelques raisons mais bon…
À la fin de l’installation on vous recommande de faire des liens symboliques pour lier la commande ruby avec l’exécutable ruby23 par exemple (mais les autres aussi).
Les prochaines commandes considéreront que les liens n’ont pas été créés.
Voici maintenant l’installation de rails, il est visiblement admis qu’il est préférable de les mettre dans un dossier de l’utilisateur (cela sera .gem). Il faut intégrer le nouveau chemin des gem installées dans le path
fichier .profile PATH=$PATH:~/.gem/ruby/2.3/bin:
ou bien à la suite des autres chemins
~/.gem/ruby/2.3/bin:
On quitte le shell et on revient et on installe rails.
$ gem23 install rails --user-install
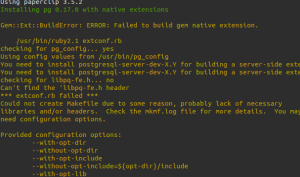
Parfois la gem nokogiri ne s’installe pas (cela a marché deux fois et raté deux fois…).
Il faut donc installer
# pkg_add libxml libxslt
et
$ gem23 install --user-install nokogiri -- --use-system-libraries --with-xml2-config=/usr/local/bin/xml2-config --with-xslt-config=/usr/local/bin/xslt-config
Dans le dossier utilisateurs par exemple je fais la commande
$ rails new appbidon
Tout se passe bien…
Jusqu’au bundle install qui rate sur rake. Pas de panique. On va dans le dossier de l’application, et on lance
$ bundle23 install --path ~/.gem
Tout se passe bien.
Je passe dans le dossier de l’app créée puis lance le serveur
$ rails23 s
À ce stade cela va échouer, mais c’est un “problème” connu des utilisateurs de rails.
Il faut installer un moteur javascript et curieusement therubyracer qui nécessite la libv8 ne s’installe pas bien (problème avec python ??)
On va donc installer nodejs.
# pkg_add node
Insérer la gem node dans le Gemfile (sous la ligne therubyracer)
fichier appbidon/Gemfile gem 'node'
Faire un
bundle23 install --path ~/.gem (dans le dossier de l'application). rails23 s
Et alleluiah le serveur démarre sur localhost:3000
Seul problème actuel en local cela va (lynx sur la machine hôte qui pointe sur localhost:3000) mais de l’extérieur cela n’est pas atteignable…
Il faut faire un bind du serveur sur l’adresse 0.0.0.0
La commande devient
rails23 s -b 0.0.0.0
On pointe un navigateur sur l’IP port 3000 et cela fonctionne.
Bon maintenant reste plus qu’à coder :-)
PS.
Merci aux aides sur internet, la liste railsfrance et le questions/réponses sur OpenBSD animé par thuban.
Je vais faire un résumé, cela sera plus simple. Voire une version en anglais et italien…
PPS.
Les commandes:
# ln -sf /usr/local/bin/XXX23 /usr/local/binXXX $ ln -sf ~/.gem/ruby/2.3/bin/XXX23 ~/.gem/ruby/2.3/bin/XXX
sont tes amies pour simplifier la vie. Et il y a encore des trucs que je n’ai pas pigé sur le pourquoi du comment.